Een verdiepende analyse in ontevredenheid met behulp van textmining
09 01 2020Met textmining kunnen we waardevolle informatie uit grote hoeveelheden tekstmateriaal halen. Met behulp van verschillende technieken zoeken we patronen en onderliggende verbanden tussen woorden en maken die inzichtelijk. Een voorbeeld: in plaats van dat je elke reactie op een open vraag in een enquête moet lezen om een beeld te krijgen wat mensen zeggen, gebruiken we de computer om de tekst voor ons te lezen en het samen te vatten. In deze blog neemt Thomas je stap voor stap mee in hoe hij textmining gebruikt om te onderzoeken wat veel voorkomende ontevredenheidspunten zijn over de huidige woningen van mensen:
De data
De data die ik gebruik komt uit een grootschalige enquête “De Grote Omgevings Test” die we in 2018 uitzetten onder 50.000 mensen in Zuid-Holland. Ik richt mij op de vraag: “Hoe tevreden bent u over uw huidige woonomgeving?”. Respondenten die “Ontevreden of “Zeer Ontevreden” invulden kregen de mogelijkheid om dit verder toe te lichten.
Stap 1: opschonen van de data
Ik begin met het opschonen van de tekstdata. Dit bestaat in dit geval uit het corrigeren van spellingsfouten, het groeperen (Lemmatisation) van woorden met een overkoepelende term (bijvoorbeeld “slechte” wordt “slecht”, “geïsoleerd” wordt “isolatie”), het verwijderen van woorden die niks toevoegen aan de inhoud van de tekst (bijvoorbeeld lidwoorden) en het verwijderen van leestekens. Een volledig foutloze tekst komt in de werkelijkheid bijna nooit voor, maar door deze technieken toe te passen probeer ik de foutmarge zo minimaal mogelijk te houden.
Stap 2: meest voorkomende woorden
Na de data preprocessing probeer ik een gevoel te krijgen wat mensen aangeven met betrekking tot ontevredenheid. Het visualiseren van de meest voorkomende woorden geeft mij een eerste impressie:
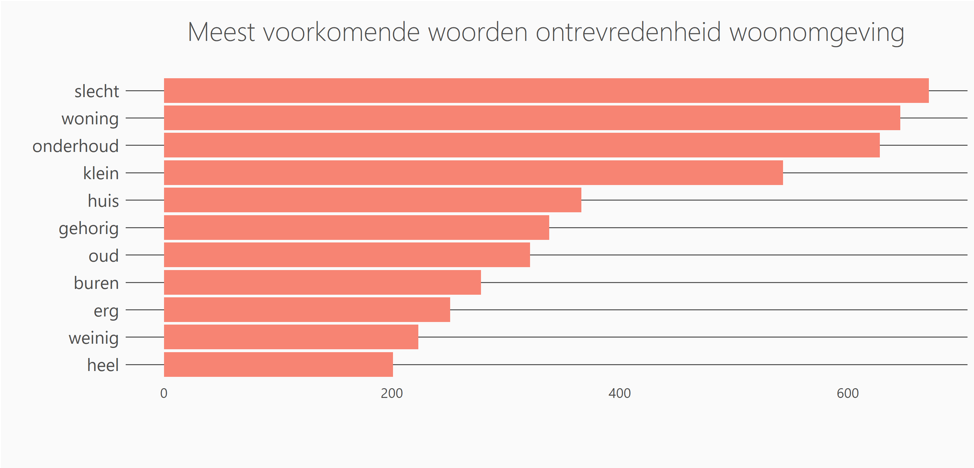
Figuur 1: meest voorkomende woorden
Ik zie dat de woorden “slecht” en “woning” het vaakst worden genoemd. De vraag gaat over ontevredenheid over hun woonomgeving, dus het is logisch dat mensen hun woning benoemen. Ook zie ik hier woorden zoals “onderhoud” en “klein” naar voren komen, die over het algemeen in een negatieve context worden genoemd.
Stap 3: bigrams
De volgende stap in de analyse is het maken van zogenaamde bigrams. Dit zijn combinaties van woorden om te zien welke woorden het vaakst bij elkaar genoemd worden. Hier kan ik een network graph van maken om de opvolging van woorden inzichtelijk te krijgen. Ik heb geen lemmatisation toegepast zodat de grafiek makkelijker te interpreteren is.
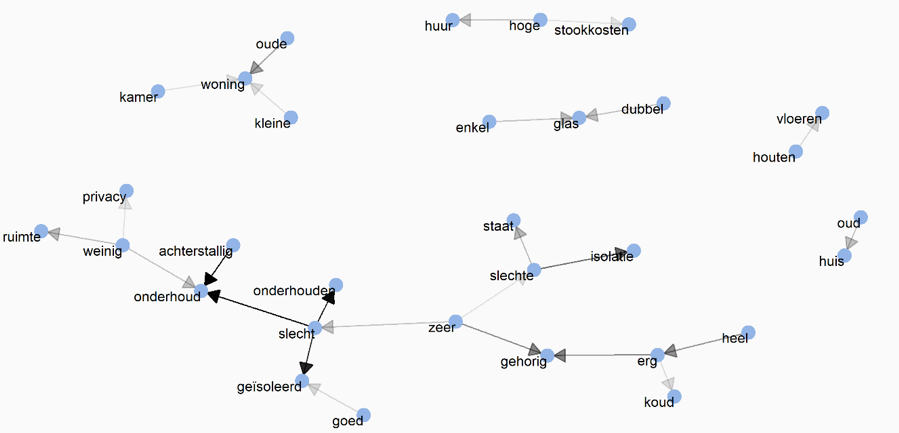
Figuur 2: network Graph huur -en koopwoningen combinaties van woorden
Hoe dikker de pijl, hoe vaker de combinatie van woorden voorkomt. De richting van de pijl geeft de leesrichting aan. Ik zie linksboven bijvoorbeeld de combinaties van woorden met het woord “woning”. Mensen geven aan dat de woning klein of oud is. Wat sterk naar voren komt in dit plaatje zijn de woorden met betrekking tot onderhoud (linksonder); “achterstallig onderhoud”, “slecht onderhoud”, “slecht onderhouden”, “slecht geïsoleerd” komen vaak voor. Als ik naar rechts kijk, zie ik ook de woorden “gehorig” en “isolatie” veel voorkomen. Hieronder een opsomming van veel voorkomende thema’s :
- Onderhoud
- Isolatie
- Gehorig
- Oude woning/ huis
- Kleine woning / huis
- Hoge kosten
Ik kan vervolgens een splitsing maken naar koopwoningen om te kijken waar mensen in een koopwoning ontevreden over zijn. Dit levert het volgende netwerk op:

Figuur 3: Network Graph koopwoningen combinaties van woorden
Ik zie hier een aantal overeenkomende associaties, maar ook een aantal nieuwe. Zo zie ik dat “weinig ruimte”, “burenoverlast” en “kleine tuin” ook problemen zijn voor mensen. Schijnbaar noemen mensen ook “houten vloeren” als knelpunt over hun woning. Als ik de antwoorden ophaal waar mensen houten vloeren noemen, zie ik dat deze in dezelfde context worden genoemd als “oude woning”.
[1] “houten vloeren en veel te gehorig door de 1933 jaar oude woning”
[2] “oud houten vloeren”
Ditzelfde doe ik voor huurwoningen:
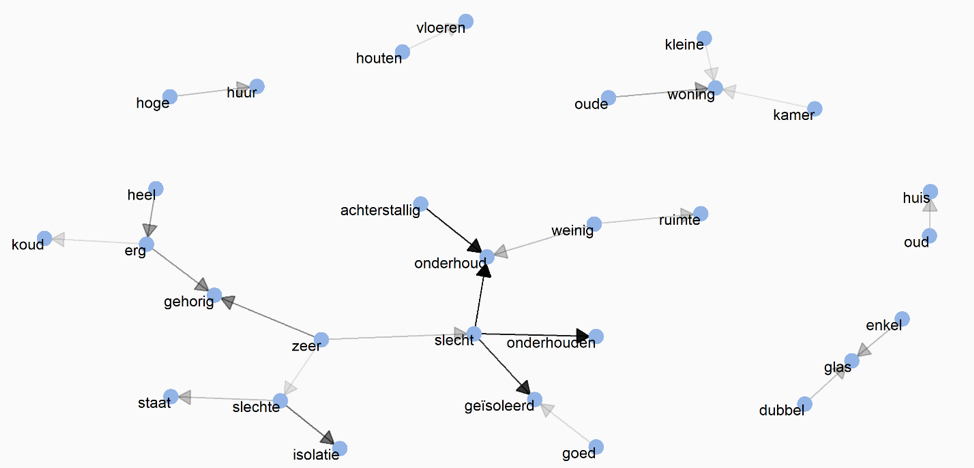
Figuur 4: network Graph huurwoningen combinaties van woorden
Ook hier komt het thema onderhoud en isolatie naar voren. Daarnaast geven mensen iets aan over de huurprijs, de staat van de woning en de hoeveelheid ruimte.
Ik kan figuur 2 (zowel huur als koopwoningen) ook omzetten naar een grafiek waar ik zie hoe vaak de combinaties worden genoemd. Zo krijg ik een beter beeld wat nou de meest genoemde combinaties van woorden zijn met betrekking tot de thema’s:
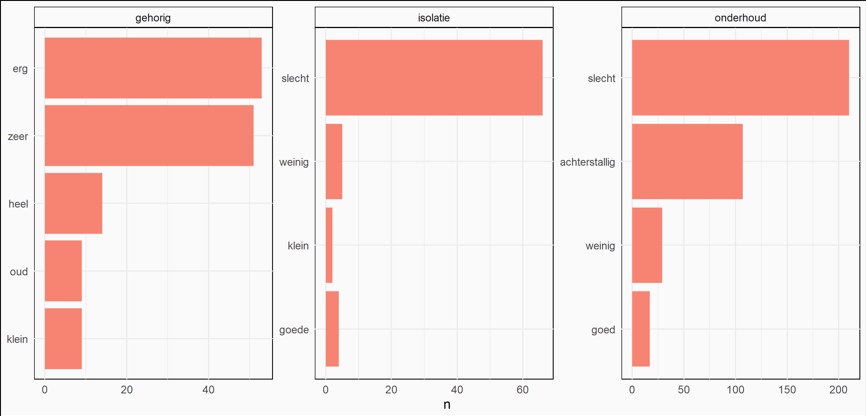
Figuur 5: meest genoemde woordencombinaties
Uit deze grafieken zie ik dat de combinaties: “erg gehorig”, “slechte isolatie” , “slecht / achterstallig onderhoud” het vaakst voorkomen.
Conclusie
Nu heb ik een goed leesbaar overzicht van de elementen waar mensen ontevreden over zijn. De gebruikte technieken in dit artikel zijn slechts het topje van de ijsberg als het gaat over de toepasbaarheid en mogelijkheden van textmining. In een volgend artikel ga ik hier dieper op in. Desalniettemin resulteerde deze analyse aantal interessante ontdekkingen met betrekking tot woningontevredenheid.