Met Text Mining op zoek naar patronen in kwalitatieve data
09 03 2021De keuze tussen een open of gesloten vraagstelling vormt een dilemma die van alle tijden is en in veel disciplines voorkomt. En of het nu om een peiling, een enquête of een referendum gaat, de voor- en nadelen komen overeen. Met Text Mining technieken proberen we patronen te herkennen in kwalitatieve data, en streven we naar de ‘best of both worlds’ op datagebied.
Waar een gesloten vraagstelling misschien weinig ruimte biedt voor nuance of een afwijkende mening, leidt het wel tot uitkomsten die ongeacht de omvang van de doelgroep eenvoudig te kwantificeren, analyseren en presenteren zijn. Tegelijkertijd brengt een open vraagstelling juist de achterliggende motieven van de doelgroep aan het voetlicht, maar kost het veel tijd om individuele verhalen te interpreteren. Text Mining biedt hierin een uitkomst, omdat je met deze technieken snel en efficiënt patronen kan ontwaren in kwalitatieve data. Zeker als je de uitkomsten koppelt aan andere informatie die je hebt over respondenten ontstaan hele nieuwe inzichten die van belang kunnen zijn in de inrichting van de woon- en leefomgeving.
Wat is Text Mining dan?
Text Mining is een methode om grote lappen tekst gestandaardiseerd en geautomatiseerd te analyseren. Tekstuele data bestaat natuurlijk al net zo lang als numerieke data, maar de meeste algoritmes kunnen alleen numerieke data verwerken. Dit komt omdat hier duidelijke wiskundige regels voor bestaan (denk aan optellen, aftrekken, vermenigvuldigen, etc.). Woorden kun je natuurlijk niet makkelijk bij elkaar optellen of van elkaar aftrekken. Gelukkig zijn de laatste jaren innovatieve algoritmes ontwikkeld en grote databases in verschillende talen ontwikkeld, waardoor nieuwe manieren ontstaan om lange teksten automatisch te kunnen verwerken. Text Mining is eigenlijk de verzamelnaam voor alle algoritmes die dit mogelijk maken.
Welke vormen van Text Mining zijn er, en hoe werken deze?
Een van de belangrijkste methoden is de sentimentanalyse. Bij een sentimentanalyse wordt gebruik gemaakt van een database waarin heel veel woorden in een bepaalde taal staan. Aan die woorden worden scores gehangen, die bijvoorbeeld de polariteit (is het een positief of een negatief woord) of de subjectiviteit (is het een mening of een feit) vertegenwoordigen. Een woord als ‘fantastisch’ heeft een positieve polariteitsscore en ook een hoge subjectiviteitsscore, want het gaat naar alle waarschijnlijkheid om een positieve mening. Tegelijkertijd krijgt een woord als ‘ziekte’ een negatieve polariteitsscore, maar ook een lage subjectiviteitsscore. Wanneer iemand een ziekte noemt wordt vaak een feitelijke diagnose omschreven, maar wel eentje die bijzonder vervelend is. Deze databases worden bijgehouden door taalkundigen van over de hele wereld en zijn vaak open-source. Door teksten tegen deze databases aan te leggen, kunnen we het sentiment meten. Dit kan bijvoorbeeld iets zeggen over hoe tevreden bewoners zijn met de woon- en leefomgeving. En als we weten van welke (type) mensen de teksten afkomstig zijn (bijvoorbeeld in een enquête), kunnen we het verschil in sentiment onder groepen mensen meten.
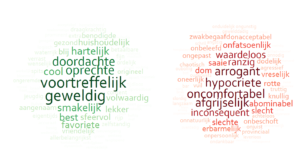
Categorisering van de polariteit van verschillende woorden in een sentimentanalyse, met links de positieve en rechts de negatieve woorden
Een andere analysevorm is topic modelling. Dat is ook weer een verzamelnaam voor verschillende analyses, maar vaak probeer je met deze analyses kernwoorden te onttrekken die aan het onderwerp van de tekst raken. Als we bijvoorbeeld tien teksten tegen elkaar aanleggen, kun je met een topic modelling-algoritme bepalen welke woorden uniek gebruikt worden in een bepaalde tekst. Hierdoor ontdek je vaak, zonder de tekst te lezen, waar een tekst over gaat. Stel de tien teksten zijn allemaal omschreven ervaringen van bewoners in tien verschillende buurten. En we kijken vervolgens welke woorden elke bewoner het vaakst gebruikt heeft. Dan valt waarschijnlijk op dat elke bewoner generieke woorden zoals ‘buurt’, ‘lawaai’ en ‘rotzooi’ gebruikt. Dat is wel interessant, maar het laat niet de unieke problematiek van een buurt zien. Met topic modelling kan je daarentegen ontdekken dat het in één bepaalde buurt juist vooral om de sociale cohesie (of het gebrek daaraan) gaat. De computer merkt namelijk dat de bewoner van deze buurt zich relatief veel opwindt over ‘mensen’ en ‘buren’, terwijl dit bij bewoners in andere buurten minder het geval is.
Wat levert dit bijvoorbeeld op?
Een praktijkvoorbeeld. Hiervoor heeft Springco Urban Analytics, een datagedreven adviesbureau in de woon- en leefomgeving, een Text Mining-analyse gedaan op resultaten uit De Grote Omgevingstest (DGOT). Respondenten hebben veel open antwoorden gegeven op enquêtevragen, zoals het door hen ervaren woonmilieu, hun positieve en negatieve associaties met de buurt en voorgestelde verbeteringen voor hun woning. Deze teksten kunnen we bovendien goed onderscheiden naar persoonskenmerken (leefstijl, levensfase, inkomen, etc.). Het zou interessant zijn om tot nieuwe hypotheses rondom het thema woongeluk en welzijn te kunnen komen.
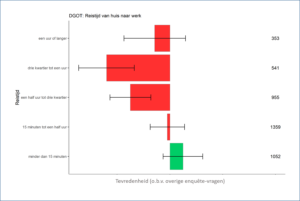
Respondenten die dichtbij hun werk wonen zijn in open antwoorden vaak positiever over hun woning
Neem bijvoorbeeld het verband tussen iemands reistijd naar werk en de mate van tevredenheid met de woning volgens onze sentimentanalyse. Hierin is duidelijk te zien dat de mensen die een relatief korte reistijd hebben gemiddeld een stuk tevredener zijn. Een interessante kanttekening is echter dat dit verband op een gegeven moment ophoudt. Mensen die een reistijd van meer dan een uur hebben zijn gemiddeld juist bijna even tevreden als de mensen met een reistijd van tussen de vijftien en dertig minuten.
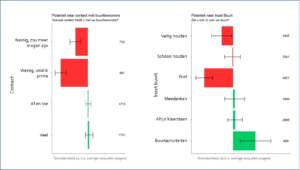
Respondenten die contact hebben met hun buren of zich voor hun buurt inzetten zijn in open antwoorden vaak positiever over hun woning
Als we vervolgens kijken naar community beleving, zien we dat inzet voor de buurt en contact met buurtbewoners gepaard gaat met een positievere woonbeleving. Mensen die weinig contact hebben met buurtbewoners zijn negatiever over hun woonsituatie dan mensen die af en toe of veel contact hebben met hun buurtbewoners. Er zijn ook mensen die aangeven weinig contact te hebben en dat ook prima vinden, maar zij hebben waarschijnlijk ook weinig affiniteit met hun buren en daarom ook niet met de buurt. Dat de meeste mensen die meer contact hebben ook tevredener zijn is een interessant inzicht waar zeker wat mee gedaan kan worden in het ontwerpen van de stad. We zouden onze steden bijvoorbeeld meer kunnen toespitsen op ontmoeting in plaats van efficiëntie.
Dit zijn wat tips van de sluier die een idee geven, maar je kan je al voorstellen dat de mogelijkheden eindeloos zijn. Dankzij Text Mining kan je veel gerichter de motieven van bewoners achterhalen. Techbedrijven gebruiken deze methodieken al om hun positionering beter te kunnen bepalen. Zij vinden tienduizend vijfsterrenwaarderingen lang niet zo waardevol als een paar honderd geschreven uitleggen, omdat hier veel meer inhoudelijke informatie over sterktes, zwaktes, kansen en uitdagingen kan worden geput. Kwalitatieve data vertegenwoordigt werkelijk een schat aan informatie. Tijd om deze zo snel mogelijk te ontginnen en op deze manier gerichter de motieven van bewoners te achterhalen. Een mooie gelegenheid om in te zetten tijdens co-creatie sessies tijdens de ontwikkeling van je plan!
Online kennissessie op donderdag 18 maart
Dit onderzoek is uitgevoerd op basis van enquête-antwoorden uit De Grote Omgevingstest. maar eigenlijk kunnen we alle soorten tekst met deze technieken onder de loep nemen. Dit doen we al voor verschillende woningcorporaties en projectontwikkelaars. Samen met Blauwhoed organiseren we op donderdag 18 maart van 13:00-13:30 (met ruimte voor vragen na afloop) een online kennissessie over dit thema, waarvoor je je hier kan aanmelden.